Improve Monitoring Efficiency
Monitoring services on an IP network can be resource-intensive, especially in cases where many of the services are not available. When a service is offline or unreachable, the monitoring system spends most of its time waiting for retries and timeouts. To improve efficiency, Meridian deems all services on an interface to be down if the critical service is down. Meridian uses ICMP as the critical service by default.
The following image shows how to use critical services to generate these events:
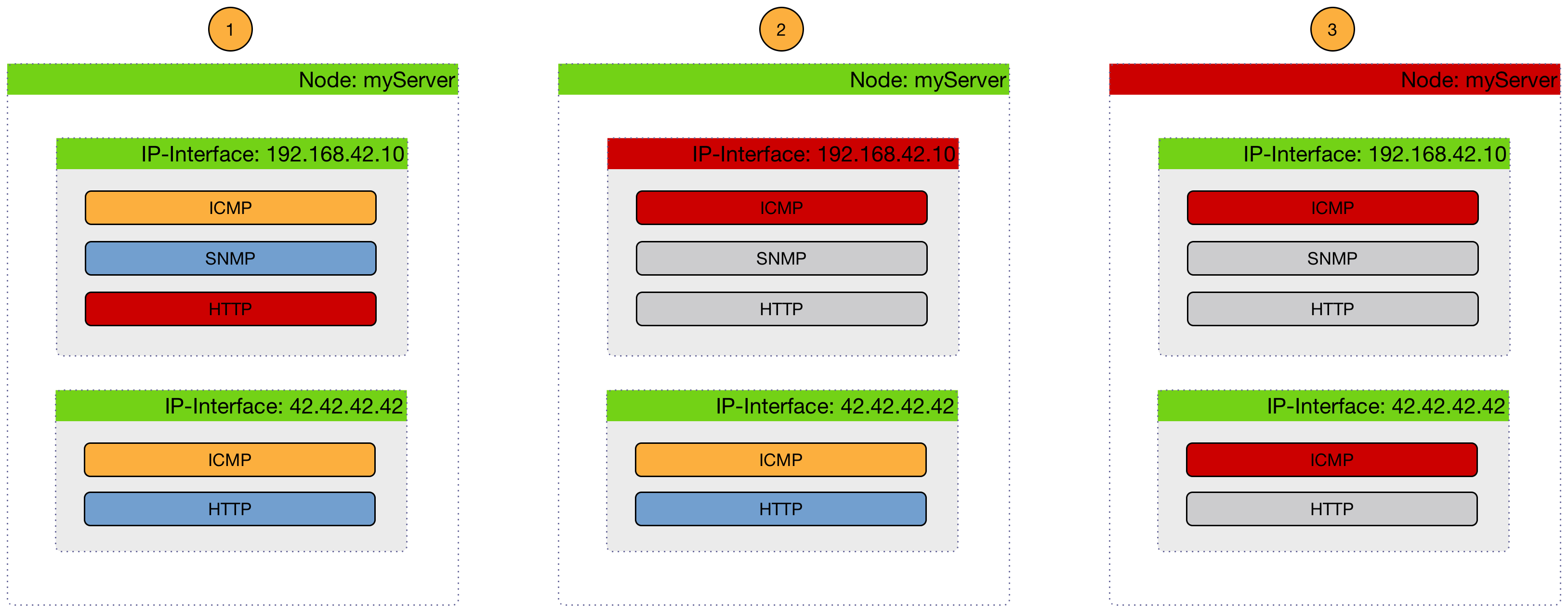
-
All critical services are up on the node; only a
nodeLostServiceevent is sent. -
A critical service on one of many IP interfaces is down; an
interfaceDownevent is sent. All other services are not tested, and no other events are sent. These services are assumed to be unreachable. -
All critical services on the node are down, and only a
nodeDownevent is sent. All other services on the other IP interfaces are not tested, and no events are sent. These services are assumed to be unreachable.
Meridian uses critical services to correlate outages to a nodeDown or interfaceDown event.
This is a global configuration setting for pollerd, and is defined in poller-configuration.xml.
It is enabled by default.
<poller-configuration threads="30"
pathOutageEnabled="false"
serviceUnresponsiveEnabled="false">
<node-outage status="on" (1)
pollAllIfNoCriticalServiceDefined="true"> (2)
<critical-service name="ICMP" /> (3)
</node-outage>| 1 | Allow node outage correlation based on a critical service. |
| 2 | (Optional) For nodes without a critical service, this option controls the polling behavior during a node outage.
If set to true, all services will be polled.
If set to false, the first service in the package that exists on the node will be polled until service is restored.
When service is restored, polling will resume for all services. |
| 3 | Define the critical service for node outage correlation. |