Alarms
Meridian monitors the state of problems with its managed entities (ME), their resources, the services they provide, as well as the applications they host; or more simply, the network. Meridian, characterizes the state of these problems as alarms.
While OpenNMS events (or messages) carry problem state attributes such as acknowledgement and severity, alarms are the indicator for problems in the network, (see also situations and Business Services).
Single Alarm Tracking Problem States

Figure 1. First occurrence of a service down problem (SNMP), alarm instantiated

Figure 2. The service down event from the poller (via clicking on alarm count)

Figure 3. Alarm is cleared immediately (no longer creating separate alarm for normal state)

Figure 4. Both service down and service restored events from the poller

Figure 5. The second occurrence of the service down problem (SNMP), alarm reduced
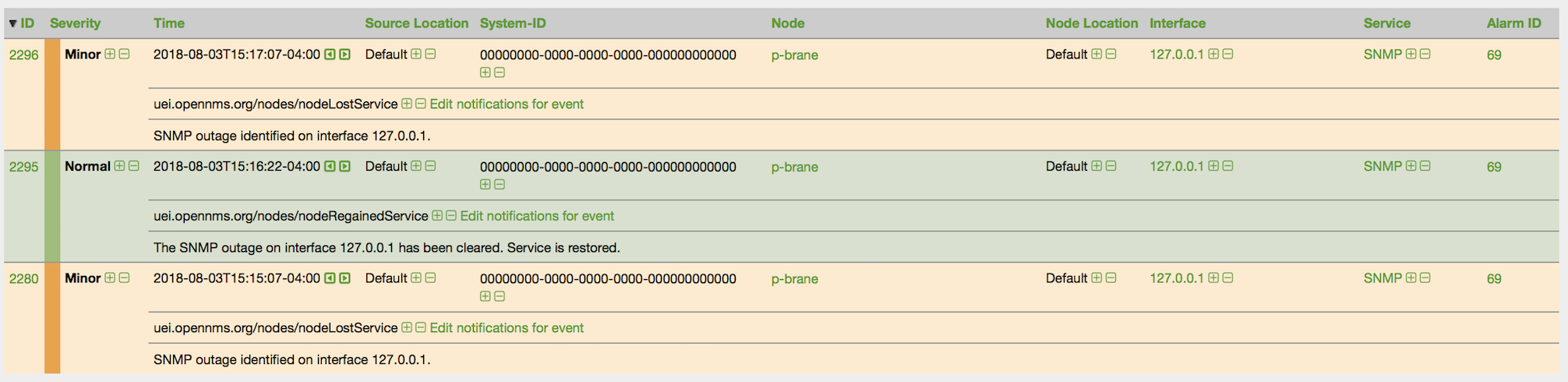
Figure 6. Both service down events and the previous service restored event from the poller

Figure 7. The alarm is again cleared immediately (notice counter does not increment)
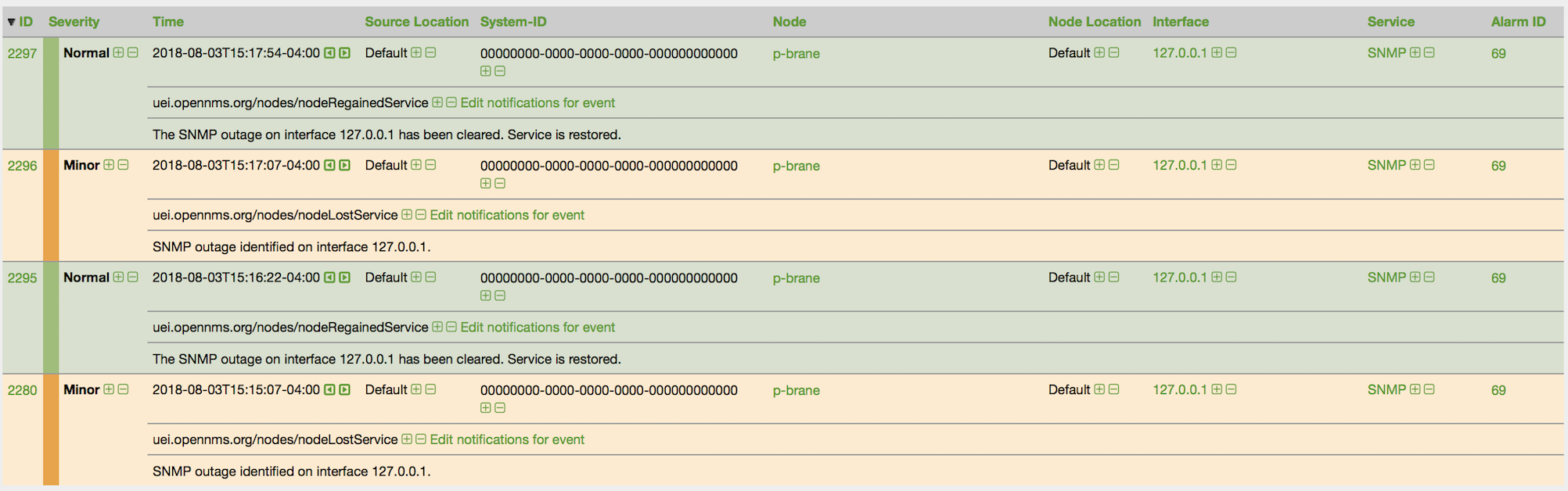
Figure 8. Both service down and restored events