Detect Short Service Outages
By default, the monitoring interval for a service is five minutes. You can use the configurable downtime model to detect short service outages, like those caused by automatic network rerouting. The downtime model lets you reduce the monitoring interval to every 30 seconds for 5 minutes when a service outage is detected. If the service comes back online within 5 minutes, a shorter outage is documented.
The image below shows two outages: the first is a service that was detected as being up after 90 seconds. The second has not yet been resolved—the monitor has not detected an available service, and was not available within the first 5 minutes (polled 10 times, every 30 seconds).
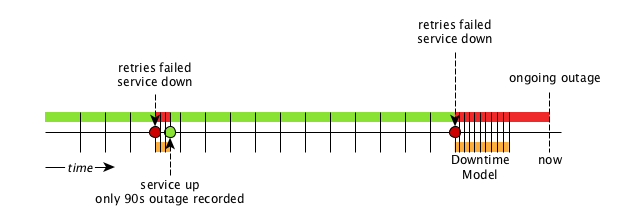
The scheduler changed the polling interval back to five minutes.
<downtime interval="30000" begin="0" end="300000" /><!-- 30s, 0, 5m --> (1)
<downtime interval="300000" begin="300000" end="43200000" /><!-- 5m, 5m, 12h --> (2)
<downtime interval="600000" begin="43200000" end="432000000" /><!-- 10m, 12h, 5d --> (3)| 1 | From 0 seconds after an outage is detected until 5 minutes, set the polling interval to 30 seconds. |
| 2 | After 5 minutes of an ongoing outage until 12 hours, set the polling interval to 5 minutes. |
| 3 | After 12 hours of an ongoing outage until 5 days, set the polling interval to 10 minutes. |
Note that after five days of an ongoing outage, the service will be polled only once per hour.
Any edits to the downtime model take effect after restarting the pollerd daemon, and apply to both existing and new outages. For example, if an existing outage is being polled every 30 seconds for five minutes, but you change the downtime model during that period to a 45-second interval, the outage will be polled every 45 seconds for the remainder of the five minutes.
Pollerd identifies the services as either up or down.